DATA ASSIMILATION FOR THE ENTIRE EARTH SYSTEM

USE DATA FROM ANY SOURCE, TEST MANY ALGORITHMS

LEARN ON LAPTOPS, RUN ON SUPERCOMPUTERS
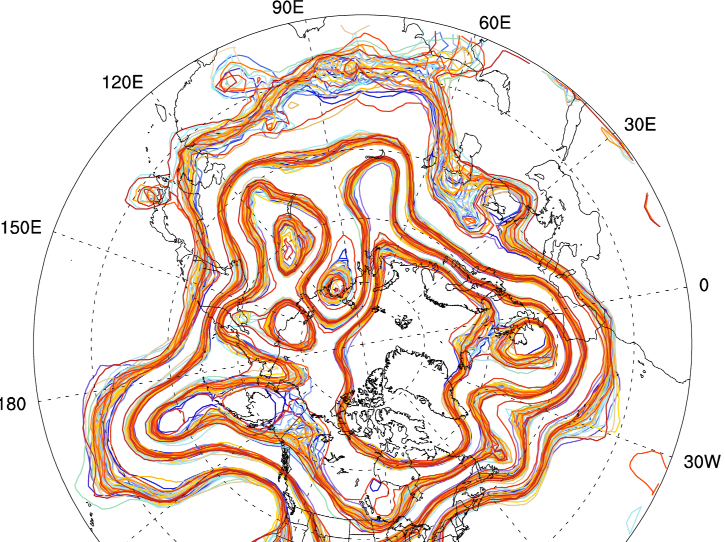
Supported models
| Lower Atmosphere | Upper Atmosphere | Ocean | Cryosphere | Land Surface | Hydrology | Conceptual |
|---|---|---|---|---|---|---|
| CAM | WACCM | POP | CICE | CLM | WRF-Hydro | Lorenz '63, '84, '96, '05 |
| WRF | GITM | ROMS | NOAH, NOAH-MP | Ikeda | ||
| WRF-Chem | Open GGCM | MITgcm-ocean | B-grid | |||
| MPAS-Atmosphere | TIE GCM | MPAS-ocean | SQG | |||
| AM2 | ROSE | FESOM | 9-variable |
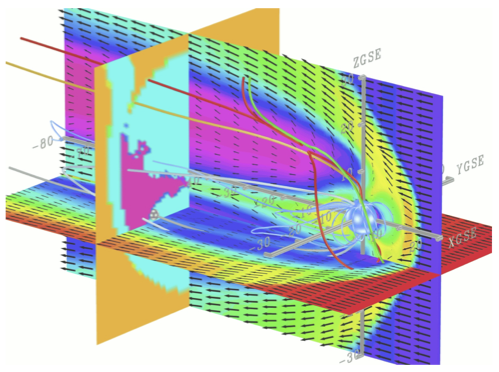
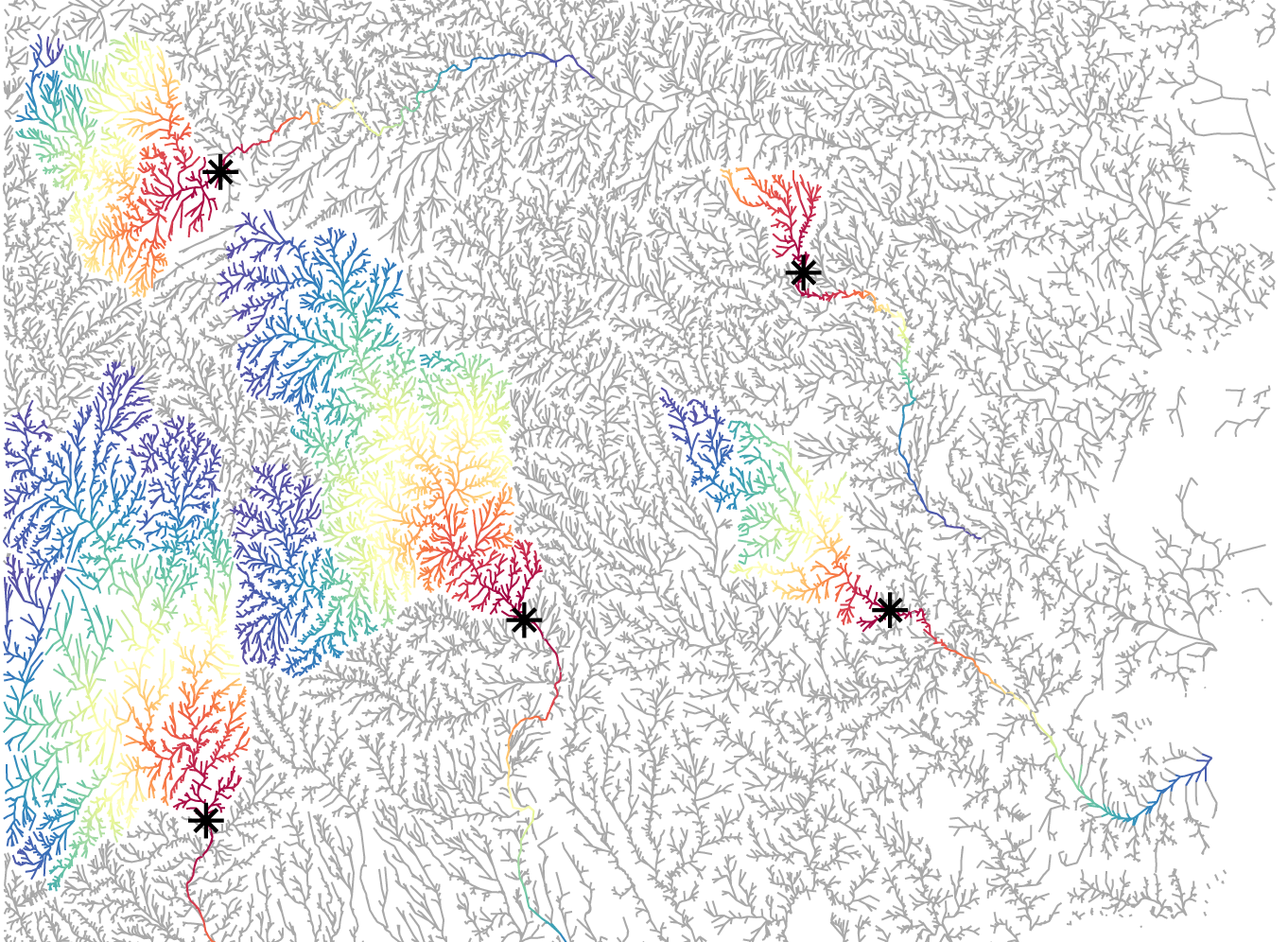
RECENT PROJECTS
Research projects involving DART