|
Table of Contents |
|
1. Introduction
2. Thin Plate Splines: Tps 3. Spatial Process Models: Krig 4. Simulating Random Fields (sim.rf) 5. Spatial Predictions for Large Data Sets
|
|
Printable version of Fields Manual
Back to Fields Home Page |
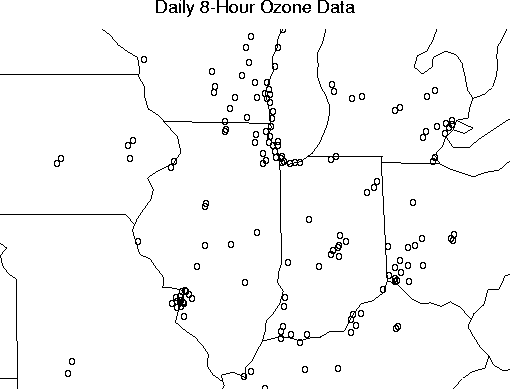
The Fields dataset ozone2 consists of daily 8-hour surface ozone measurements during the summer of 1987 for approx. 150 locations in the Midwest.
# Plot the data with a map of the area.
usa( xlim= range( ozone2$lon.lat[,1]), ylim= range( ozone2$lon.lat[,2]))
points( ozone2$lon.lat, pch="o")
title("Daily 8-Hour Ozone Data", cex=0.85)
It will be handy to create a correlogram before we continue.
ozone.cor <- COR( ozone2$y)
mean.tps <- Tps( ozone2$lon.lat, ozone.cor$mean, return.matrices = F)
sd.tps <- Tps( ozone2$lon.lat, ozone.cor$sd, return.matrices = F)
day16 <- c( ozone2$y[16,])
# -- Logical vector to remove missing values from day16.
idn <- !is.na( day16)
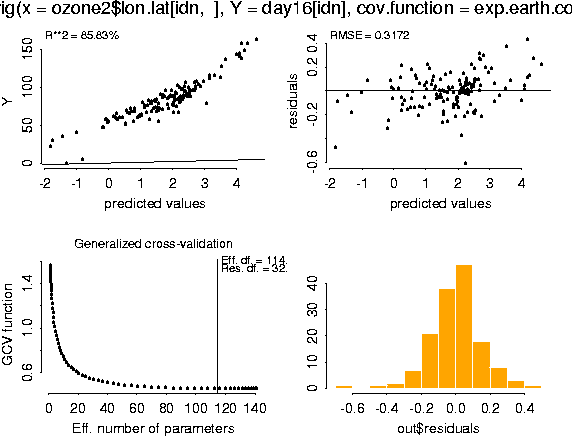
fit <- Krig( ozone2$lon.lat[idn, ], day16[idn], cov.function=exp.earth.cov, theta = 343, sd.obj=sd.tps, mean.obj=mean.tps, m=1) summary( fit)
Krig(x = ozone2$lon.lat[idn, ], Y = day16[idn], cov.function = exp.earth.cov,
m = 1, mean.obj = mean.tps, sd.obj = sd.tps, theta = 343)
Number of Observations: 147
Number of unique points: 147
Degree of polynomial null space ( base model): 0
Number of parameters in the null space 1
Effective degrees of freedom: 114.7
Residual degrees of freedom: 32.3
MLE sigma 0.289
GCV est. sigma 0.3172
MLE rho 7.538
Scale used for covariance (rho) 7.538
Scale used for nugget (sigma^2) 0.0835
lambda (sigma2/rho) 0.01108
Cost in GCV 1
GCV Minimum 0.4585
Y is standardized before spatial estimate is found
Residuals:
min 1st Q median 3rd Q max
-0.6091 -0.07774 0.003612 0.08233 0.433
REMARKS
Covariance function: exp.earth.cov